51吃瓜-吃瓜网站
2025届统计学专业本科生秦蒙恩在模式识别领域Top期刊Pattern Recognition上发表研究成果“A3-FPN: Asymptotic content-aware pyramid attention network for dense visual prediction”,该成果在51吃瓜
杨晓慧教授指导下完成,该生将赴美国伊利诺伊大学芝加哥分校攻读博士学位。

论文链接://www.sciencedirect.com/science/article/pii/S0031320326007582
代码链接://github.com/mason-ching/A3-FPN
研究成果聚焦基于均衡稀疏表示的深度学习方法在密集视觉预测中的应用。在密集视觉预测任务(目标检测、语义分割等)中,采用特征金字塔网络及其变体通过“自上而下”或“自上而下+自下而上”的路径来融合多尺度特征,已成为业界标配。然而,这套标准方案尚存在三个可以进一步完善的地方:(1)信息随着网络加深丢失。通过信息论中的数据处理不等式可以严格证明,路径越长,信息损失的上界越大。(2)采样针对性不强,导致边界模糊与目标位移。无论是上采样还是下采样,都是上下文无关的固定操作。它们不考虑图像内容,简单地复制或丢弃像素,导致物体边界在融合时变得模糊,小目标特征极易被淹没,造成定位框漂移或漏检。(3)简单相加,一定程度上忽略了特征模式的差异。不同层级的特征,其表示的“模式”可能截然不同。简单地将它们逐元素相加,相当于把不同“语言”的信息硬凑在一起,导致类别内特征不一致,模型容易产生混淆和误判。这三个问题共同导致了一个结果:模型在简单场景下表现尚可,然而遇到小目标、密集场景或复杂边界,性能就急剧下降。现有优化尝试大都集中在改进主干网络或损失函数上,然而忽略了如何做到充分且紧凑的均衡特征融合这个“咽喉要道”。
为解决上述问题,该研究工作提出了一种渐近内容感知金字塔注意力网络(A3-FPN)。其核心思想是用横向扩展的“列”结构,渐进式地将每一层特征从所有其他层中“解耦”出来,并在融合与重组阶段全程注入“内容感知”的注意力机制。所提出的方法适用CNN、Transformer等多种网络架构,并能灵活用于目标检测、分割等多种密集视觉预测任务。在COCO、VisDroneDet-2019, Cityscapes等多个领域通用公开数据集上刷新SOTA,且推理速度更快。
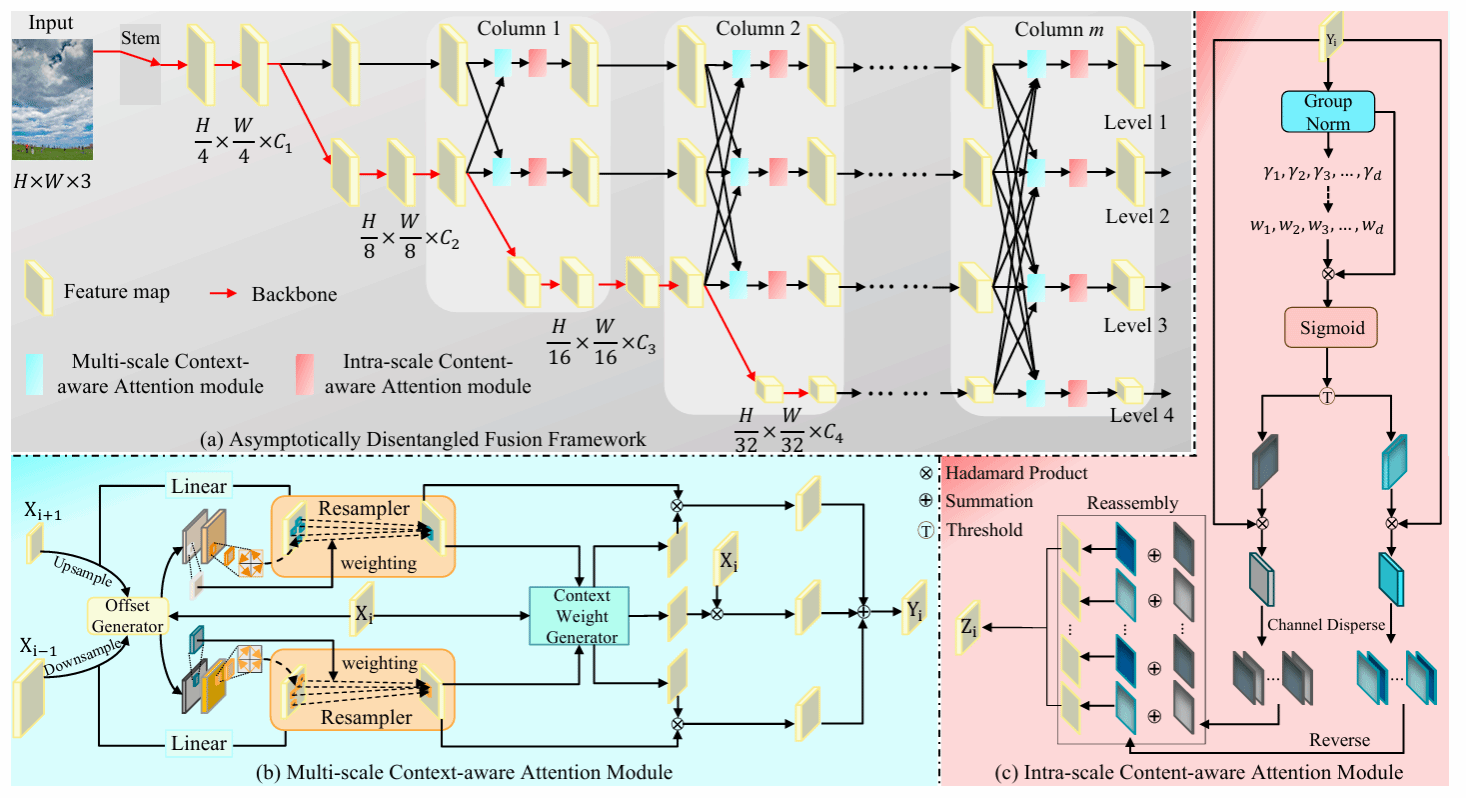
本文提出的A3-FPN总体框架图
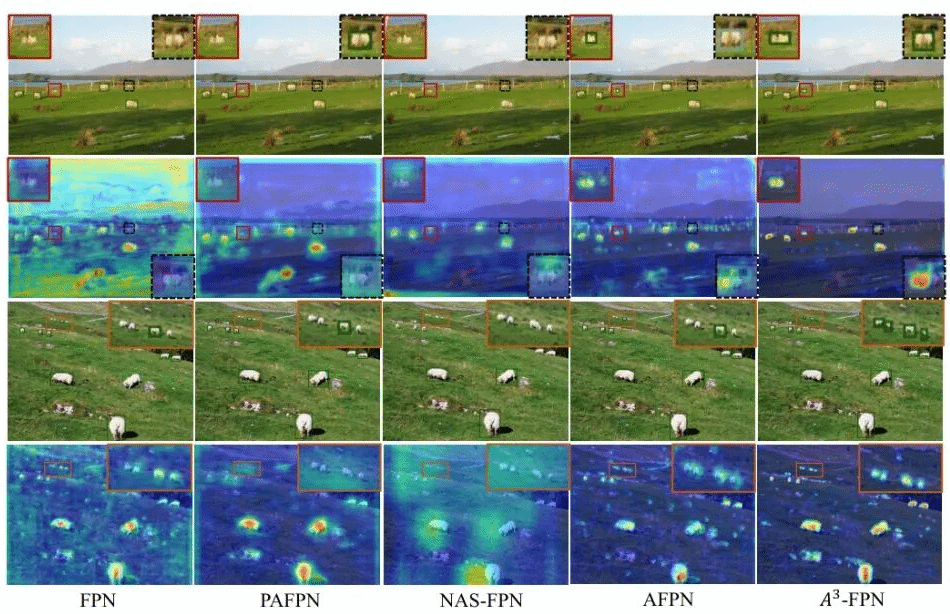
A3-FPN和其他方法在目标检测任务上的对比效果
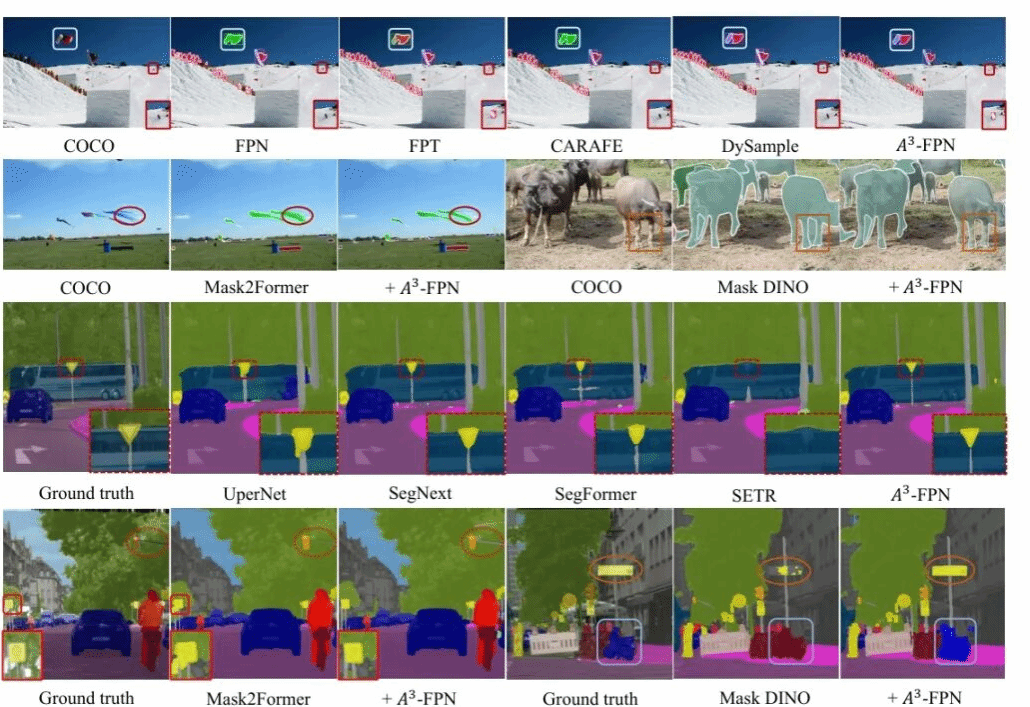
A3-FPN和其他方法在实例分割和语义分割任务上的对比效果